Introduction – Data Lakes Vs. Data Warehouses
Data has emerged as a cornerstone of modern business operations in the digital era, catalyzing innovation, strategy, and informed decision-making. The exponential growth in data volume & complexity has underscored the pivotal role of effective data management. This blog is intended to explore the key differences between Data Lakes Vs. Data Warehouses.
The Rise of Data in Business:
Never before has information been as abundant and transformative as it is today. Every customer click, social media interaction, and system-generated record contributes to an intricate tapestry of data. This deluge of information presents both a challenge and an opportunity for organizations seeking to extract actionable insights from this wealth of data.
Understanding Data Management:
At the heart of this challenge lies the discipline of data management—a strategic approach encompassing processes, technologies, and methodologies to collect, store, process, and analyze data. Within this landscape, two primary architectures, data lakes, and data warehouses, play pivotal roles in organizing and leveraging data assets.
Unveiling Data Lakes Vs. Data Warehouses:
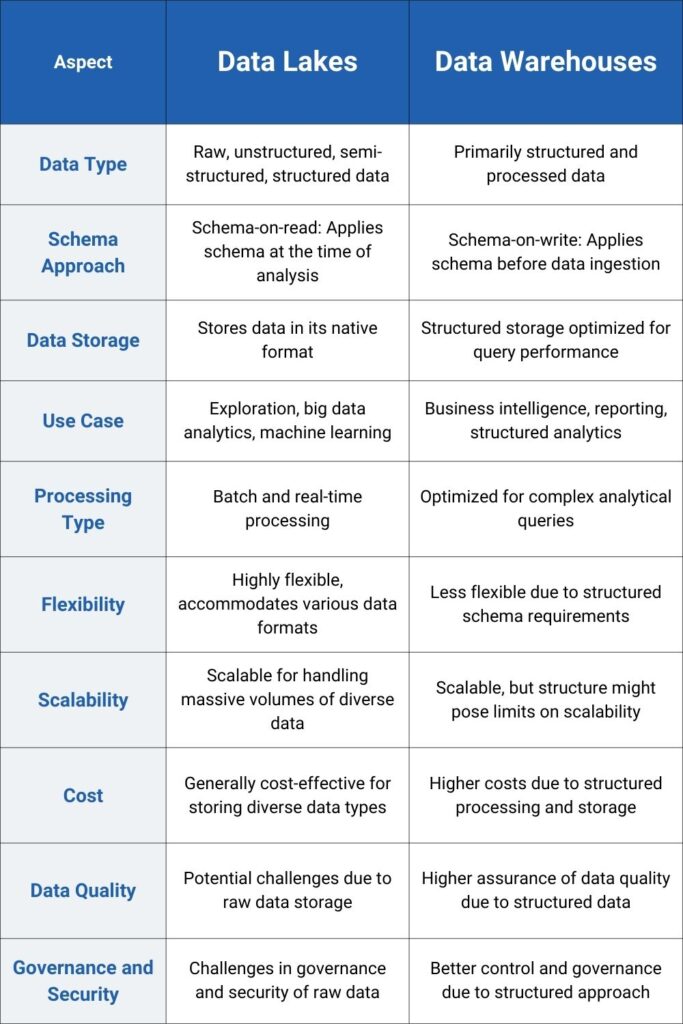
Data lakes and data warehouses represent distinct paradigms in data management. Data lakes embody flexibility, housing raw, unstructured data, while data warehouses prioritize structured data for analytical purposes. Understanding the nuances and functionalities of these systems is crucial for businesses navigating the complex terrain of data utilization.
In this exploration, we’ll delve into the essence of Data Lakes Vs. Data Warehouses, dissecting their architectures, strengths, and applications. By comparing these fundamental pillars of data management, we aim to provide insights to empower businesses to make informed choices aligned with their specific needs and objectives.