In today’s data-driven world, businesses rely heavily on effective data management and analytics to gain valuable insights and make informed decisions. Data warehousing has emerged as a critical component in this process, offering a centralized repository for storing and processing large volumes of data. In this blog post, we will delve into the world of data warehousing and explore two prominent solutions: Snowflake Vs. Redshift. These two platforms have garnered significant attention and are often the subject of comparison and debate among data professionals.
Join us as we journey to understand Snowflake vs. Redshift – Strengths, Weaknesses, and Nuances, helping you make an informed choice for your data warehousing needs.
Introduction to Snowflake
Snowflake is a cloud-based data warehousing platform that has gained widespread popularity recently due to its unique architecture and robust features. It was designed from the ground up for the cloud, making it a versatile and scalable solution for businesses of all sizes.
Architecture and Key Features
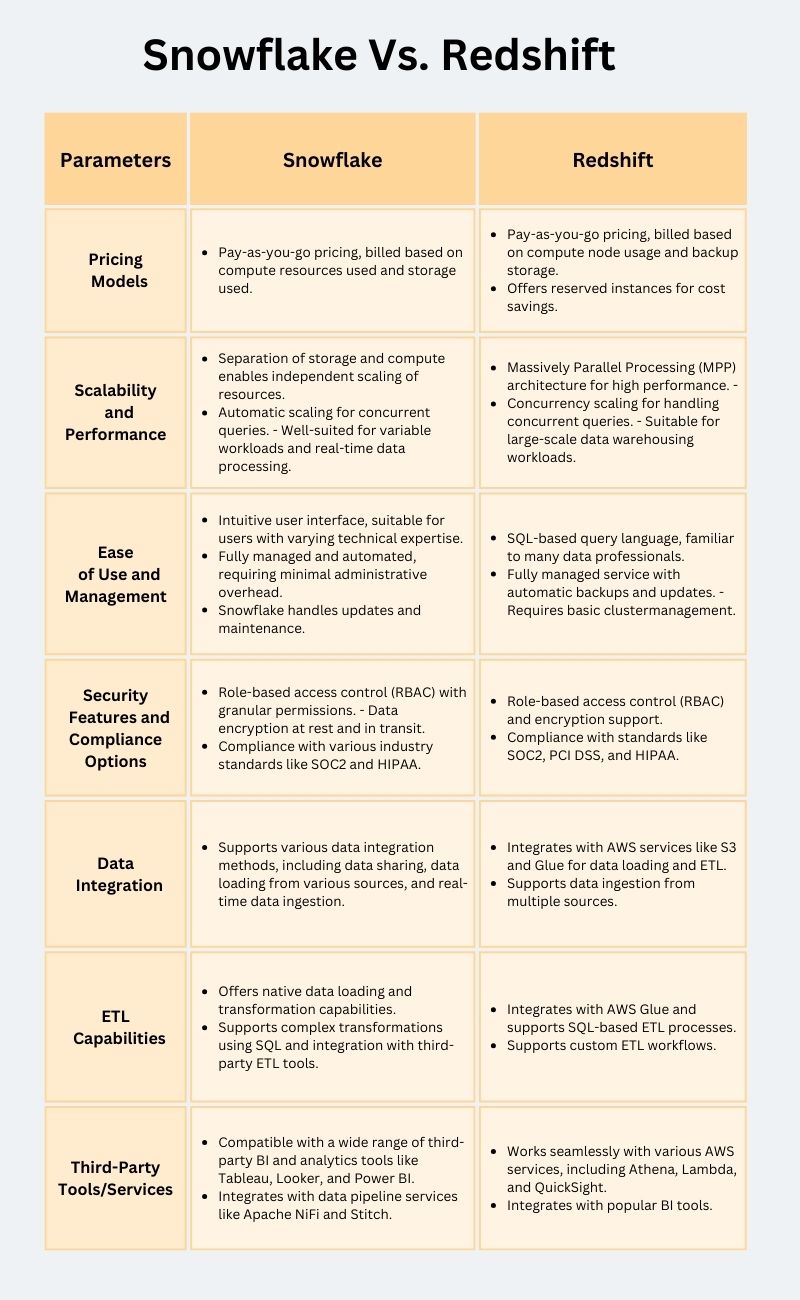
Multi-cluster, Shared Data Architecture: Snowflake’s architecture separates storage and computing, allowing users to scale independently. This means you can store your data in a centralized repository while scaling compute resources as needed for processing queries. This separation enhances efficiency and cost-effectiveness.
Zero-Copy Cloning: Snowflake enables you to create multiple, read-only copies of your data without duplicating it. This feature is incredibly useful for creating sandboxes, performing tests, and ensuring data consistency.
Data Sharing: Snowflake makes sharing data securely with other organizations or departments easy without complex ETL processes. This is particularly valuable for collaboration and data monetization.
Automatic Scaling: Snowflake automatically scales resources up or down based on query complexity and workload. This ensures consistent performance even during peak usage.
Concurrency Control: Snowflake’s unique approach to concurrency control allows multiple users to run queries simultaneously without contention, improving query performance in a multi-user environment.
Advantages and Use Cases
Scalability: Snowflake’s cloud-native architecture allows for seamless scalability, making it an ideal choice for businesses with fluctuating workloads.
Ease of Use: Snowflake’s intuitive interface and SQL support make it accessible to users with varying technical expertise.
Data Sharing: The platform’s data-sharing capabilities are particularly advantageous for organizations that need to collaborate or share data externally.
Cost Efficiency: Snowflake’s pay-as-you-go pricing model means you only pay for the resources you use, which can lead to cost savings compared to traditional data warehousing solutions.
Real-time Analytics: Snowflake’s ability to handle real-time data streams and semi-structured data makes it suitable for modern analytics and data-driven decision-making.
Snowflake’s versatility and adaptability make it a compelling choice for many use cases, from traditional business intelligence to advanced analytics and machine learning applications. As we further explore its capabilities, you’ll better understand how Snowflake can empower your data warehousing initiatives.
Overview of Amazon Redshift
Introduction to Amazon Redshift
Amazon Redshift is a powerful, fully managed data warehousing solution that Amazon Web Services (AWS) offers. It is designed to handle large-scale data analytics and reporting workloads with high performance and scalability. Redshift is particularly popular among enterprises for its seamless integration with other AWS services and ability to process complex queries efficiently.
Architecture and Key Features
Columnar Storage: Redshift uses a columnar storage format, which stores data column by column rather than row by row. This optimizes query performance, allowing Redshift to read only the columns necessary for a query, reducing I/O and improving overall efficiency.
Massively Parallel Processing (MPP): Redshift employs MPP architecture, which involves breaking down queries into smaller tasks and distributing them across multiple nodes in a cluster. This parallel processing capability accelerates query execution, making it suitable for large datasets.
Automatic Compression: Redshift automatically compresses data to reduce storage costs and improve query performance. It uses different compression algorithms based on data type and distribution to achieve optimal results.
Concurrency Scaling: Redshift can automatically and elastically scale compute resources to handle concurrent user queries and high workloads, ensuring consistent performance even during peak usage.
Integration with AWS Ecosystem: Redshift integrates with other AWS services like Amazon S3 for data storage, AWS Glue for ETL (Extract, Transform, Load) processes, and AWS IAM for security management. This makes it a robust choice for organizations already utilizing AWS.
Advantages and Use Cases
Scalability: Redshift’s ability to scale up or down based on workload demands suits businesses with variable query loads or rapidly growing data volumes.
Performance: Its columnar storage and MPP architecture make Redshift highly performant, enabling complex queries on large datasets to be executed quickly.
Ease of Use: Redshift provides a familiar SQL interface, making it accessible to data analysts and SQL-savvy professionals.
Data Warehousing for AWS Workloads: Redshift offers a natural fit for organizations using AWS services extensively, as it can seamlessly integrate with other AWS tools and services.
Business Intelligence and Analytics: Redshift is commonly used for business intelligence and data analytics applications, including data exploration, reporting, and dashboarding.
Amazon Redshift’s robust architecture and integration with the AWS ecosystem make it a compelling choice for organizations looking to manage and analyze their data efficiently at scale. Its advantages in performance and scalability make it particularly well-suited for data-intensive businesses and analytics-driven decision-making processes.
Snowflake Vs. Redshift
Limitations and Challenges Associated with Snowflake:
Cost: While Snowflake’s pay-as-you-go pricing model can be cost-effective, it may become expensive for organizations with extremely high query volumes or significant data storage needs. Users should carefully monitor their usage to control costs.
Complexity for Simple Workloads: For organizations with straightforward and simple workloads, Snowflake’s feature-rich architecture may appear complex, leading to over-provisioning and higher costs.
Vendor Lock-In: Snowflake is a cloud-native solution, and while it offers flexibility in choosing the cloud provider, once a business commits to Snowflake, migrating to another platform can be challenging and costly.
Limited On-Premises Support: Snowflake primarily operates in the cloud, which may not be suitable for organizations that require on-premises or hybrid solutions due to compliance or data residency requirements.
Limitations and Challenges Associated with Redshift:
Lack of Real-Time Processing: Redshift is optimized for batch processing and may not be the best choice for organizations requiring real-time data analytics.
Complex Scaling: While Redshift provides scalability options, managing and scaling clusters can be complex, particularly for users who are new to the platform.
Data Loading Overheads: Loading large volumes of data into Redshift can be time-consuming, and optimizing data loading processes may require additional ETL work.
Vendor Lock-In: Similar to Snowflake, Redshift ties users to the AWS ecosystem, potentially limiting flexibility for businesses seeking multi-cloud or hybrid solutions.
Vikrant Chavan is a Marketing expert @ 64 Squares LLC having a command on 360-degree digital marketing channels. Vikrant is having 8+ years of experience in digital marketing.